Structure of a BIFF 8 file
In this section we will describe the basic structure of a BIFF 8 file. For additional information on the complete BIFF file format please refer to either msdn.microsoft.com or to the MSDN library CD.
Basic Structure of a BIFF File
The basic structure of a BIFF file is shown below:
Start Global data
Font table
Color table
Format table
Style table
.
.
.
End Global data
Start Worksheet data
Data that is specific to the sheet goes here.
This data often refers to the global table.
Styles, for example, are stored in the global table and are referenced here by index.
End Worksheet data
Start Next Worksheet data
.
.
.
End Next Worksheet data
This is the structure of the documented stream. Excel has other streams. Some are not documented and some (like summary information) are. For our purposes we will only handle the data in the main stream, the WorkBook Stream.
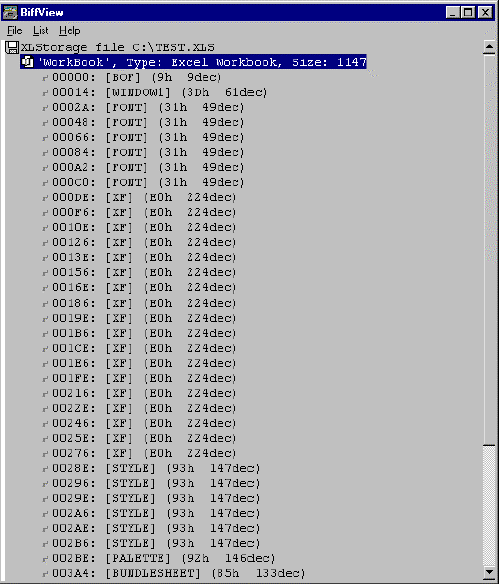
Shown below is a typical Excel file (written out by Objective Grid) as seen in BiffView, a utility that ships with the Excel Software Development Kit (SDK). The sequence of global and local records are detailed above. Note that the global records are grouped together and yet are discrete. This makes them conceptually similar to a table that is accessible by index.
The structure of each actual record is quite simple. The first part is always a record identifier.
Record Identifier
With Excel (BIFF 8) the record identifier is 2 bytes (a word). The different fields that are read and written by Excel are detailed in the Excel SDK. Each of these is denoted by a 2 byte constant.
Record Length
The record length varies from record to record. This value is the size of the total record less the size of the fixed header for each record. The fixed header is the sum of the record identifier size and the record length size, i.e. 4 bytes with BIFF 8.
For example, let us take the case of a sample record, the BOF (beginning of file) record, defined in the Excel SDK as follows:
The BOF record marks the beginning of the Book stream in the BIFF file. It also marks the beginning of record groups (or “substreams” of the Book stream) for sheets in the workbook. For BIFF2 through BIFF4, you can determine the BIFF version from the high-order byte of the record number field, as shown in the following table. For BIFF5, BIFF7, and BIFF8 you must use the vers field at offset 4 to determine the BIFF version.
The SDK documentation describes each of the constituent parts of the Excel SDK in detail. For our purposes we will examine the binary dump of this field from a typical Excel File. This is shown below:
01F14: [BOF] (9h 9dec) Binary dump of BOF field from an Excel file
09 08 10 00 00 06 10 00 d3 10 cc 07 c9 00 00 00
06 00 00 00
To study the general structure, we are interested in only the first four bytes. In the above case these are:
09 08 10 00
The first two bytes in this byte sequence stand for the record type (in this case typeBOF). According to the Excel SDK, we copy these declarations (for the fields that we use) into gxexhdr.h:
#define typeBOF 0x0809
This is what we have considering that the byte sequence is reversed on Little Endian machines. The first two bytes are typeBOF.
Now let us look at the next two bytes. Taking byte swapping into account we have 0x0010 or in decimals 16 (bytes). You can see that, apart from the fixed 4 byte header, 16 bytes form the body of the record. The interpretation of each of these bytes is given in the Excel SDK. Based on this we decipher these bytes and convey data to Objective Grid. When writing, the reverse occurs.
Structure of the Read/Write Mechanism
Let us examine the structure of the read mechanism first. When the grid reads in an Excel file it knows the basic structure of the file as detailed above (types and lengths). Once it reads the type and the length, it checks to see if it can handle this type. If it can be handled at all, each type can be handled by exactly one handler. Two different types of objects handle data. One object is called handler and the other is called table. Handlers are typically for local worksheet data and tables are for global data.
The Objective Grid Excel code looks in a map to see if there is a handler for the record type. If one exists, the stream is read and the data is retained and interpreted. If not, the grid performs a seek (based on the record length that was read from the record header) and goes on to look at the next entry. This continues until the file is read completely.
Two maps are defined in the application— one for handlers and the other for tables. These maps are composed of macros in a manner that is very similar to that of CWnd message maps. A typical map structure for tables and handlers is shown below:
BEGIN_GX_EXCEL_MAP(CGXExcelTable)
GX_EXCEL_MAP_ENTRY(typeFont, CGXExcelFontTable, 2)
GX_EXCEL_MAP_ENTRY(typeStyle, CGXExcelStyleTable, 2)
GX_EXCEL_MAP_ENTRY(typeXF, CGXExcelXFTable, 2)
GX_EXCEL_MAP_ENTRY(typePalette, CGXExcelColorTable, 2)
GX_EXCEL_MAP_ENTRY(typeFormat, CGXExcelFormatTable, 2)
GX_EXCEL_MAP_ENTRY(typeSST, CGXExcelSSTTable, 2)
GX_EXCEL_MAP_ENTRY(typeBoundSheet, CGXExcelBoundSheetTable, 2)
END_GX_EXCEL_MAP()
BEGIN_GX_EXCEL_MAP(CGXExcelHandler)
GX_EXCEL_MAP_ENTRY(typeLabel, CGXExcelLabelHandler, 2)
GX_EXCEL_MAP_ENTRY(typeNumber, CGXExcelNumberHandler, 2)
GX_EXCEL_MAP_ENTRY(typeRk, CGXExcelRkHandler, 2)
GX_EXCEL_MAP_ENTRY(typeMulRk, CGXExcelMulRkHandler, 2)
GX_EXCEL_MAP_ENTRY(typeColInfo, CGXExcelColInfoHandler, 2)
GX_EXCEL_MAP_ENTRY(typeRow, CGXExcelRowHandler, 2)
GX_EXCEL_MAP_ENTRY(typeFormula, CGXExcelFormulaHandler, 2)
GX_EXCEL_MAP_ENTRY(typeBOF, CGXExcelBOFHandler, 2)
GX_EXCEL_MAP_ENTRY(typeBlank, CGXExcelBlankHandler, 2)
GX_EXCEL_MAP_ENTRY(typeMulBlank, CGXExcelMulBlankHandler, 2)
GX_EXCEL_MAP_ENTRY(typeSSLabel, CGXExcelLabelSSTHandler, 2)
GX_EXCEL_MAP_ENTRY(typeDimension, CGXExcelDimensionHandler, 2)
GX_EXCEL_MAP_ENTRY(typeWindow2, CGXExcelWindow2Handler, 2)
GX_EXCEL_MAP_ENTRY(typeMergedCell, CGXExcelMergedCellsHandler, 2)
END_GX_EXCEL_MAP()
Each map macro entry has three values. The first is the type of record that this entry can handle. The second is the object type to be used when handling this entry. (Remember that the map merely maps a record type to an object that can handle it). The third (rather redundant) value specifies the size of the record type data that is to be used for comparison. With the current version (BIFF 8) this value can always be taken as two bytes. However, in anticipation of changes in future versions of Excel, we designed this product with flexibility and facility in mind.
If you were to add support for another table or handler, you would simply add another entry to this map. If you do not intend to add support for any additional fields you can use the maps from one of the samples.
The lookup sequence is very simple. Let us look at some code that shows this inside the grid:
// Read the type of the record.
// Try to locate the handler.
CGXExcelHandler* pHandler = GXExGetHandlerMap()->LocateHandler(wType);
CGXExcelTable* pTable = GXExGetTableMap()->LocateHandler(wType);
ASSERT((pHandler && pTable) == FALSE);
// It has to be either a table or a regular record handler.
// You can’t have both kind of handlers simultaneously.
One advantage of having this structure is that it affords easy changes to the type of handlers that can be added. It makes it very easy to add support for fields that are not supported by the product out of the box. It also makes it easy to log details about fields that are not read in for debugging purposes.
Writing is slightly different since the writing code lays out the file structure and calls the correct handlers and tables to build the .xls file. Again a map controls the order in which the writing takes place. This map merely controls the sequence of the write and calls the same handlers as the write code to handle the actual write. Let us take a look at this map.
This is defined not in the application but in CGXExcelReaderImpl. (For more details on this class, please refer to the online help.)
CGXWriteEntry* CGXExcelReaderImpl::GetWriteTableMap()
{
static CGXWriteEntry _map[] =
{
GX_EXCEL_WRITEMAP_ENTRY(typeBOF, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeWindow1, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typePalette, gxTable)
GX_EXCEL_WRITEMAP_ENTRY(typeFont, gxTable)
GX_EXCEL_WRITEMAP_ENTRY(typeXF, gxTable)
GX_EXCEL_WRITEMAP_ENTRY(typeStyle, gxTable)
GX_EXCEL_WRITEMAP_ENTRY1(typePalette, gxTable, gxPassTwo)
GX_EXCEL_WRITEMAP_ENTRY(typeBoundSheet, gxTable)
GX_EXCEL_WRITEMAP_ENTRY(typeEOF, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(ixfNULL, gxHandler)
};
return _map;
}
// handlers for local fields
CGXWriteEntry* CGXExcelReaderImpl::GetWriteHandlerMap()
{
static CGXWriteEntry _map[] =
{
GX_EXCEL_WRITEMAP_ENTRY(typeBOF, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY1(typeBoundSheet, gxTable,
gxBoundSheetSpecialPass)
GX_EXCEL_WRITEMAP_ENTRY(typeColInfo, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeDimension, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeRow, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeRk, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeWindow2, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeMergedCell, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(typeEOF, gxHandler)
GX_EXCEL_WRITEMAP_ENTRY(ixfNULL, gxHandler)
};
return _map;
}
One rather confusing aspect of these maps requires mentioning. You can see from above that although there are two maps (one for tables and one for handlers), they both contain handlers and tables. There is no essential difference between the two as there is with the read maps. The read maps contain tables or handlers. The reason for this is that while the global structure of an Excel file is largely composed of table structures, some fields are handler fields (BOF and EOF, for example). Remember that this demarcation is something that we created for convenience and is not laid out in the Excel SDK. Therefore, these maps contain both types of objects. However, you can readily see that in each one, one type of object is more predominant than the other.
Another interesting aspect is that these maps can be used to write data in multiple passes. For example, in some cases we may have to calculate offsets and then later write these out. The write code can check for pass one and do the actual write with pass two. Passes are more an implementation detail than anything else; you will not have to use these directly in most cases.
NOTE >> In the event that you do have to use passes, please contact our support team for further assistance. The implementation details of passes are not documented and might change in a future version.