SourcePro C++ 12.0
SourcePro® C++ API Reference Guide
SourcePro C++
Documentation Home
SourcePro C++ 12.0 |
SourcePro® C++ API Reference Guide |
SourcePro C++ Documentation Home |
Converts a string into a particular normalized Unicode form, and detects whether a string is already in a particular form. More...
#include <rw/i18n/RWUNormalizer.h>
Public Types | |
| enum | NormalizationForm { FormNFD, FormNFKD, FormNFC, FormNFKC } |
| enum | CheckResult { Yes, No, Maybe } |
Static Public Member Functions | |
| static RWUString | normalize (const RWUString &source, NormalizationForm form=FormNFC) |
| static CheckResult | quickCheck (const RWUString &source, NormalizationForm form=FormNFC) |
| static CheckResult | quickFcdCheck (const RWUString &source) |
RWUNormalizer converts a string into a particular normalized form, and detects whether a string is already in a particular form.
Many text strings can be represented by more than one sequence of Unicode characters. This is because the Unicode standard recognizes two types of character equivalence:
á (Unicode code point U+00E1) and the canonical decomposition formed by the letter a and a combining acute accent symbol (Unicode code points U+0061 and U+0301). Another example of canonical equivalence is between Korean hangul syllables and the jamo characters that compose them.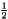 (Unicode code point
(Unicode code point U+00BD) corresponds to the nominal sequence 1/2 (Unicode code points U+0031, U+2044, and U+0032). Another example of compatibility equivalence is between circled and uncircled versions of characters.These two types of character equivalence give rise to four normalization forms:
Each normalization form produces a unique representation for a given string.
Note that two of the normalization forms, NFD and NFKD, replace composite characters with their canonical decompositions. The other two forms, NFC and NFKC, perform the opposite operation--they replace sequences of characters with canonical composites, where possible.
Also note that two of the normalization forms, NFD and NFC, do not affect compatibility characters. These normalization forms are non-lossy; that is, a string may be converted to NFD or NFC with no loss of information. The other two forms, NFKD and NFKC, replace compatibility characters with their nominal equivalents. As compatibility characters may differ in appearance from their nominal equivalents, information may be lost in converting a string to NFKD or NFKC. In other words, converting to NFKD or NFKC is a lossy operation.
#include <rw/i18n/RWUNormalizer.h> #include <rw/i18n/RWUConversionContext.h> #include <iostream> using std::cout; using std::endl; int main() { // Indicate string literals are encoded according to // ISO-8859-1. RWUConversionContext context("ISO-8859-1"); // Use implicit conversion to build a string. RWUString str("The French for \"student\" is \"élève.\""); // Determine whether the string is in NFD form. RWUNormalizer::CheckResult result; result = RWUNormalizer::quickCheck(str, RWUNormalizer::FormNFD); // If necessary, normalize the string. if (result != RWUNormalizer::Yes) { cout << "Normalizing to NFD..." << endl; str = RWUNormalizer::normalize(str, RWUNormalizer::FormNFD); } else { cout << "String is already in NFD." << endl; } // else return 0; } // main
Program Output:
Normalizing to NFD...
The quickCheck() and quickFcdCheck() return a CheckResult value to indicate whether a string is in a particular form.
A NormalizationForm value indicates a particular normalization form, as defined by the Unicode Standard Annex #15, "Unicode Normalization Forms," http://www.unicode.org/reports/tr15/.
| static RWUString RWUNormalizer::normalize | ( | const RWUString & | source, | |
| NormalizationForm | form = FormNFC | |||
| ) | [static] |
Converts the characters contained in source into the normalization form specified by form, and returns a new string containing the normalized characters.
When converting a string to any of the normalization forms, normalize() leaves US-ASCII characters unaffected, and replaces deprecated characters. normalize() never introduces compatibility characters.
| RWUException | Thrown if there are any errors. |
| static CheckResult RWUNormalizer::quickCheck | ( | const RWUString & | source, | |
| NormalizationForm | form = FormNFC | |||
| ) | [static] |
Determines whether source is in the normalization form specified by form. Returns Yes if source is in form, No if source is not in form, and Maybe if no determination can be made quickly.
| RWUException | Thrown if there are any errors. |
| static CheckResult RWUNormalizer::quickFcdCheck | ( | const RWUString & | source | ) | [static] |
Determines whether source is in Fast C or D (FCD) form. Strictly speaking, FCD is not a normalization form, since it does not specify a unique representation for every string. Instead, it describes a string whose raw decomposition, without character reordering, results in an NFD string. Thus, all NFD, most NFC, and many unnormalized strings are already in FCD form. Such strings may be collated via RWUCollator without further normalization.
Returns Yes if source is FCD, No if source is not FCD, and Maybe if no determination could be made quickly.
| RWUException | Thrown if there are any errors. |
© Copyright Rogue Wave Software, Inc. All Rights Reserved.
Rogue Wave and SourcePro are registered trademarks of Rogue Wave Software, Inc. in the United States and other countries. All other trademarks are the property of their respective owners.
Contact Rogue Wave about documentation or support issues.