4.3 Explicit Conversions
A converter is an object that converts text from one encoding to another. The Internationalization Module provides two converter classes:
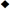 RWUToUnicodeConverter
RWUToUnicodeConverter converts text from any recognized encoding to UTF-16, in the natural endian order for the platform in use.
An
explicit conversion uses an instance of
RWUToUnicodeConverter or
RWUFromUnicodeConverter to specify how a particular conversion should be performed. The following sections describe how to create and manipulate converters.
4.3.1 Creating Converters
A converter instance is associated with an encoding at construction time. This association cannot be changed once a converter object is instantiated. For example, the following code creates an
RWUToUnicodeConverter instance that converts from ISO-8859-1 to UTF-16:
RWUToUnicodeConverter fromIso_8859_1("ISO-8859-1");
This code constructs an
RWUFromUnicodeConverter converter that converts from UTF-16 to Shift-JIS:
RWUFromUnicodeConverter toShiftJis("Shift-JIS");
The encoding names recognized by the Internationalization Module may be accessed programmatically, as described in
Section 4.2.
4.3.2 Explicitly Converting to Unicode
Class
RWUToUnicodeConverter converts text from any recognized encoding to
UTF-16. An instance of this class can be used to convert byte sequences that represent characters in a specific
character encoding into the
code unit sequences that represent those characters in the UTF-16
character encoding form.
RWUString provides constructors that accept text and an
RWUToUnicodeConverter instance to use to convert the text to UTF-16:
RWUToUnicodeConverter fromAscii("US-ASCII");
RWUString str = RWUString("hello", fromAscii);
Similarly, some
RWURegularExpression constructors accept an
RWUToUnicodeConverter instance used to convert the pattern data to UTF-16. (See Section 8.4 for more information on regular expressions.)
RWUToUnicodeConverter also provides explicit
convert() methods that accept a byte sequence in the associated encoding and a reference to an
RWUString to hold the result of the conversion to UTF-16. For example, assuming
source holds text encoded in ASCII, this code converts the byte sequence to UTF-16:
RWUToUnicodeConverter fromAscii("US-ASCII");
RWUString target;
fromAscii.convert(source, target);
The convert() method appends the results of a conversion to a target buffer. The convert() method also accepts a Boolean flush argument, with a default value of true. When flush is true, convert() flushes its internal buffers to the target buffer and clears its internal state. For modal encodings such as ISO-2022, clearing the internal state ensures that the next call to convert() can expect the source text to begin in the source encoding’s default, unshifted state.
Calling convert() once with a value of true for flush is useful when converting a piece of text in its entirety from a source encoding to UTF-16. In contrast, convert() may be used to fill a target buffer in a piecemeal fashion. Repeatedly calling convert() with a value of false for flush, then calling it once with a value of true, causes convert() to flush its buffers and clear its internal state only at the end of a multipart conversion process.
4.3.3 Explicitly Converting from Unicode
Class
RWUFromUnicodeConverter converts text from
UTF-16 to any recognized
character encoding. An instance of this class can be used to convert
code unit sequences that represent characters in the UTF-16
character encoding form into the byte sequences required to represent those characters in a specific character encoding.
RWUString provides a
toBytes() method that accepts an
RWUFromUnicodeConverter instance, and returns an
RWCString containing the byte sequence produced when the contents of the
RWUString are converted using the given converter. For example, assuming
source is an
RWUString:
RWUFromUnicodeConverter toShiftJis("Shift-JIS");
RWCString target = source.toBytes(toShiftJis);
RWUFromUnicodeConverter also provides an explicit
convert() method that accepts UTF-16 source text and a reference to an object to hold the converted byte sequence. For example, assuming
source holds text encoded in UTF-16, this code converts its contents to Shift-JIS and holds the results in a Standard C++ Library string:
RWUFromUnicodeConverter toShiftJis("Shift-JIS");
std::string target;
toShiftJis.convert(source, target);
The
convert() method also accepts a Boolean
flush argument that may be used to flush the internal buffers of a converter and clear its internal state. The default value is
true. See
Section 4.3.2 for more information.
4.3.4 Conversion Errors
A conversion simply maps characters from a source encoding to a target encoding. Normally this is a straightforward process of replacing all the code point values for characters in the source encoding with the code point values for those characters in the target encoding. However, errors can occur in this process. For example, the character being converted may not have a representation in the target encoding, or the code units in the source string may be impossible to interpret as a code point value in the source encoding. When errors such as these occur, the converter can respond in several ways:
stop the conversion process and throw an exception
skip over the offending code units, without appending anything to the output buffer
substitute for the offending code units by appending a specific substitution sequence to the output buffer
escape the offending code units by appending a numeric representation of the code units to the output buffer
For both
RWUToUnicodeConverter and
RWUFromUnicodeConverter, the default error-handling response is to substitute for the offending character.
RWUToUnicodeConverter uses
U+FFFD as its substitution sequence.
RWUFromUnicodeConverter uses a substitution sequence appropriate for the target encoding. For example, the substitution sequence for most ASCII-based encodings is
0x1a. You can change the default substitution sequence for a conversion from Unicode by calling
RWUFromUnicodeConverter::setSubstitutionSequence().
To change a converter’s error-handling behavior, call method RWUToUnicodeConverter::setErrorResponse() or method RWUFromUnicodeConverter::setErrorResponse(). Each of these methods accepts an enum value. The set of available enum values depends on the direction of the converter. The function RWUToUncodeConverter::setErrorResponse() accepts the following enum values:
RWUToUnicodeConverter::Stop Stops the conversion process on error, and throws an
RWUException.
RWUToUnicodeConverter::Skip Silently skips over any illegal sequences, without writing to the target buffer.
RWUToUnicodeConverter::Substitute Substitutes illegal sequences with the Unicode substitution character, U+FFFD.
RWUToUnicodeConverter::Escape Replaces any illegal sequences with an Xhh escaped hexadecimal representation of the bytes that comprise the illegal sequence; for example, X09XA0.
The function RWUFromUnicodeConverter::setErrorResponse() provides a similar set of error-handling tactics, but supports a wider variety of escaping options to facilitate working with different target encodings:
RWUFromUnicodeConverter::Stop Stops the conversion process on error, and throws an
RWUException.
RWUFromUnicodeConverter::Skip Silently skips over any illegal sequences, without writing to the target buffer.
RWUFromUnicodeConverter::Substitute Substitutes illegal sequences with the current substitution sequence. The default substitution sequence depends on the target encoding. For ASCII-based encodings, the default substitution sequence is 0x1A. The setSubstitutionSequence() method allows you to specify the substitution sequence.
RWUFromUnicodeConverter::EscapeNativeHexadecimal Replaces illegal sequences with a %UX escaped hexadecimal representation of the code units that comprise the illegal sequence; for example, %UFFFE%U00AC. Note that a code point represented by a surrogate pair is escaped as two hexadecimal values; for example, %UD84D%UDC56. If the target encoding does not support the characters {U,%}[A-F][0-9], an illegal sequence is replaced by the substitution sequence.
RWUFromUnicodeConverter::EscapeJavaHexadecimal Replaces illegal sequences with a \uX escaped hexadecimal representation of the code units that comprise the illegal sequence; for example, \uFFFE\u00AC. Note that a code point represented by a surrogate pair is escaped as two hexadecimal values; for example, \uD84D\uDC56. If the target encoding does not support the characters {u,\}[A-F][0-9], an illegal sequence is replaced by the substitution sequence.
RWUFromUnicodeConverter::EscapeCHexadecimal Replaces illegal sequences with a \uX escaped hexadecimal representation of the code units that comprise the illegal sequence; for example, \uFFFE\u00AC. Note that a code point represented by a surrogate pair is escaped as a single hexadecimal value; for example, \u00023456. If the target encoding does not support the characters {u,\}[A-F][0-9], an illegal sequence is replaced by the substitution sequence.
RWUFromUnicodeConverter::EscapeXmlDecimal Replaces illegal sequences with a &#DDDD; escaped decimal representation of the code units that comprise the illegal sequence; for example, ¬. Note that a code point represented by a surrogate pair is escaped as a single decimal value without zero padding; for example, 𣑖. If the target encoding does not support the characters {&,#,;}[0-9], an illegal sequence is replaced by the substitution sequence.
RWUFromUnicodeConverter::EscapeXmlHexadecimal Replaces illegal sequences with a &#XXXX; escaped hexadecimal representation of the code units that comprise the illegal sequence; for example, ¬. Note that a code point represented by surrogate pair is escaped as a single hexadecimal value without zero padding; for example, 𒍅. If the target encoding does not support the characters {&,#,x,;}[0-9], an illegal sequence is replaced by the substitution sequence.
4.3.5 Saving and Restoring the Error Response State
Both
RWUToUnicodeConverter and
RWUFromUnicodeConverter provide
saveErrorResponseState() methods that save the current error handling state of a converter using
RWUToUnicodeConverter::ErrorResponseState and
RWUFromUnicodeConverter::ErrorResponseState. You can use these methods to save the current error response state prior to calling
setErrorResponse(). (See
Section 4.3.4.) The provided
restoreErrorResponseState() methods restore the saved state. For example:
RWUToUnicodeConverter converter;
RWUToUnicodeConverter::ErrorResponseState state =
converter.saveErrorResponse();
converter.setErrorResponseState(RWUToUnicodeConverter::Stop);
converter.restoreErrorResponseState(state);
The saved state from one converter may be used to set the state on another converter. However, this operation may not be safe in future versions of the Internationalization Module.
4.3.6 Resetting Converters
At the conclusion of a successful call to convert() with the flush argument set to true (the default), a converter is automatically reset to a default, initial state. Sometimes, however, it may be necessary to reset a converter explicitly using the provided methods RWUToUnicodeConverter::reset() and RWUFromUnicodeConverter::reset(). For example:
if
convert() has thrown an exception in response to an error, you should ensure the converter is in the default state before using it again
if you are using a converter to fill a target buffer in a piecemeal fashion, and you want to abandon that conversion process to begin another, you should reset the converter
if you are copying a converter, and want to be sure the copy is in the default state, you should call
reset()