3.4 Representing Strings
In the Internationalization Module,
RWUString provides a container for text encoded using the UTF-16
character encoding form of the Unicode
character set.
RWUString derives from
RWBasicUString in the Essential Tools Module of SourcePro Core, which manages a basic array of RWUChar16 values.
3.4.1 RWBasicUString and RWCString
RWBasicUString is similar to
RWCString. For example:
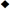
Both classes have methods
append(),
prepend(),
insert(),
remove(), and
replace() for modifying a string.
Both classes also have methods
first(),
last(),
index(),
rindex(), and
contains() that search for characters or strings of characters contained with a string.
Both classes have methods
compareTo() for lexically ordering strings.
RWBasicUString differs from
RWCString in that an
RWBasicUString instance contains a series of Unicode characters encoded in UTF-16, while an
RWCString instance contains bytes encoded in an arbitrary encoding.
RWBasicUString also performs conversion between UTF-16 and UTF-8. Because
RWBasicUString contains UTF-16, its API has some methods that
RWCString does not. For example:
Methods
requiresSurrogatePair(),
isHighSurrogate(), and
isLowSurrogate() indicate whether a 21-bit Unicode code point requires a
surrogate pair of UTF-16 code units. Most characters can be represented in the UTF-16 encoding form with a single 16-bit code unit. Only characters in the range 0x10000 to 0x10FFFF must be represented with a surrogate pair of two UTF-16 code units.
Method
computeCodePointValue() returns the appropriate RWUChar32 code point given a surrogate pair of RWUChar16 code units.
Methods
highSurrogate() and
lowSurrogate() return the first and second surrogate RWUChar16 code units for a given RWUChar32 code point.
Methods
compareCodeUnits() and
compareCodePoints() perform code unit and code point ordering of strings, respectively. Code unit ordering of two strings may differ from code point ordering if either string contains surrogate pairs.
Methods
codeUnitLength() and
codePointLength() return the number of code units or code points in a string. The standard
length() method is equivalent to
codeUnitLength().
Method
toUtf8() returns an
RWCString containing a UTF-8 representation of the string.
Method
toUtf32() returns a
std::basic_string templatized on RWUChar32 containing a UTF-32 representation of the string.
Method
toWide() returns an
RWWString containing a UTF-16 or UTF-32 representation of the contents of the string. The representation depends on the size of
wchar_t. If
sizeof(wchar_t) is
2, the
RWWString is encoded in UTF-16. If
sizeof(wchar_t) is
4, the
RWWString is encoded in UTF-32.
Method
validateCodePoint() throws an
RWConversionErr if a given RWUChar32 code point is not a valid Unicode character, or returns the code point if it is valid. This method can be used to validate a code point value anywhere one is passed to a method.
3.4.2 Memory Management in RWBasicUString
In typical usage, an
RWBasicUString instance owns and manages the memory required to hold an array of RWUChar16 values. Like
RWCString,
RWBasicUString normally copies input data to an internal buffer. This usage is both safe and convenient.
In some cases, however, such as constant strings or large strings, it may be more efficient to avoid this initial copy by having
RWBasicUString use an externally-supplied buffer. Therefore,
RWBasicUString can also be constructed with two alternate memory management strategies:
An
RWBasicUString instance can reference an external buffer in a read-only fashion. In this case, a client supplies the constructor with a
Duration value of
Persistent. Any attempt to modify the external buffer causes
RWBasicUString to copy its contents to an internal buffer. This strategy is primarily used to treat static arrays or arrays of some other long storage duration as
RWBasicUString instances. For example:
// At file scope
static RWUChar16 acronym = [ 0x0052, 0x0057, 0x0000 ];
RWBasicUString
getAcronymAsUString()
{
return RWBasicUString(acronym, RWBasicUString::Persistent);
}
An
RWBasicUString instance can assume ownership of an external buffer, and use it in a read-write fashion. To pass ownership of a buffer to an
RWBasicUString, a client supplies the
RWBasicUString constructor with an
RWBasicUString::Deallocator object that can be used to deallocate the buffer. (See
Section 3.4.2.1.) This strategy is reminiscent of that offered by
std::auto_ptr<T>, except that
RWBasicUString implements copy construction and assignment via reference counting. An
RWBasicUString mutator modifies the external buffer directly if its capacity is large enough. Otherwise, the mutator copies the buffer's contents to an internal buffer, deallocates the external buffer, then modifies the internal buffer.
Note that in both cases, although the client’s choice of constructor determines the initial memory management strategy,
RWBasicUString will abandon an externally-supplied buffer in favor of an internal buffer as necessary.
3.4.2.1 Creating and Using Deallocators
Passing ownership of a buffer to an
RWBasicUString involves supplying the
RWBasicUString with an
RWBasicUString::Deallocator object.
RWBasicUString::Deallocator is an abstract base class that cannot be instantiated directly. Instead, a deallocator can be created in one of two ways:
An
RWBasicUString::StaticDeallocator object wraps a pointer to a class static method or a global function. As a convenience,
RWBasicUString supplies three such functions:
USE_DELETE(),
USE_FREE(), and
USE_NONE(). For example, the following code creates an
RWBasicUString::StaticDeallocator that invokes
delete[] to deallocate string buffers. These buffers are returned from a third-party library that allocates buffers via
new:
// Create a deallocator. It will be re-used by multiple
// RWBasicUString instances.
RWBasicUString::StaticDeallocator
deallocator(RWBasicUString::USE_DELETE);
// Return RWBasicUStrings that reference externally-supplied
// buffers.
RWBasicUString
getStringFromOutsideSource()
{
RWUChar16 *array = callToOutsideSource();
return RWBasicUString(array, &deallocator);
}
The subclass can deallocate string buffers in the manner of its choice, to match the manner in which the buffers are allocated.
The use of
RWBasicUString::StaticDeallocator allows the client to choose
delete[],
free(), or custom memory-management mechanisms. The use of an externally supplied deallocation method can also be used to satisfy the heap management requirements of MS-Windows dynamic linked libraries, which in some situations may create their own heap in addition to that of the calling process.
3.4.2.2 Null Termination
Given sufficient capacity,
RWBasicUString adds a null terminator to any non-static array passed to it. This terminating null is not considered part of the contents, and is not included in the count returned by
length().
3.4.3 RWUString and RWBasicUString
RWUString extends
RWBasicUString in the Essential Tools Module of SourcePro Code.
RWUString is used throughout the API in the Internationalization Module to support locale-sensitive string searching and sorting, string normalization, and conversions between UTF-16 and hundreds of other encodings--all functionality added to
RWBasicUString. For example, the comparison methods on
RWBasicUString simply compare the numerical values of the individual code units or code points, but
RWUString can be used in conjunction with
RWUCollator in the Internationalization Module to perform locale-sensitive collation (
Chapter 6).
RWUString also has access to the comprehensive set of properties for each -Unicode code point in the
Unicode Character Database, so methods such as
toUpper() and
toLower() behave in a locale-sensitive manner.
3.4.4 Creating an RWUString
RWUString instances can be constructed from:
a null-terminated sequence of
char, RWUChar16, or
RWUChar32 values
a sequence of
char, RWUChar16, or
RWUChar32 values of a specified length that may contain embedded nulls
RWUString inherits the memory management options of
RWBasicUString. See
Section 3.4.2 for more information.
3.4.5 Converting to Unicode
When an
RWUString is constructed from a non-Unicode character or string, the non-Unicode character or string is converted into Unicode. Some
RWUString constructors accept
RWUToUnicodeConverter arguments to specify explicitly how to convert from a non-Unicode string to a Unicode string. For example:
RWUToUnicodeConverter fromAscii("US-ASCII");
RWUString str("Hello World", fromAscii);
The constructor converts the string literal from US-ASCII to Unicode; the new
RWUString str contains the Unicode representation of
Hello World.
Non-Unicode strings can also be converted implicitly by specifying a default conversion context. For example:
RWUToUnicodeConversionContext fromAsciiContext("US-ASCII");
RWUString str = "hello";
See Chapter 4 for more information on conversion.
3.4.6 Converting from Unicode
RWUString provides the
toBytes() method that accepts an
RWUFromUnicodeConverter instance, and returns an
RWCString containing the byte sequence produced when the contents of the
RWUString are converted into the specified encoding. For example, assuming
source is an
RWUString:
RWUFromUnicodeConverter toShiftJis("Shift-JIS");
RWCString target = source.toBytes(toShiftJis);
The new
RWCString target contains bytes representing characters encoded in Shift-JIS.
RWUString instances can also be converted implicitly by specifying a default conversion context and calling
toBytes() with no arguments. For example:
RWUFromUnicodeConversionContext toShiftJisContext("Shift-JIS");
RWCString target = source.toBytes();
The stream insertion operator for
RWUString also performs conversions. It writes the sequence of bytes that are produced when the contents of a string are converted into the encoding specified by the currently active
RWUFromUnicodeConversionContext. For example, assuming
str is an
RWUString:
RWUFromUnicodeConversionContext toShiftJisContext("Shift-JIS");
std::cout << str << std::endl;
See
Chapter 4 for more information on conversion.
3.4.7 Escape Sequences
RWUString provides the
unescape() method that replaces hexadecimal character escapes with their corresponding Unicode characters. The recognized escape sequences are shown in
Table 1. The value of any other escape sequence is the value of the character that follows the backslash.
Table 1 – Recognized Escape Sequences
Escape Sequence | Unicode |
\uhhhh | 4 hexadecimal digits in the range [0-9A-Fa-f] |
\Uhhhhhhhh | 8 hexadecimal digits |
\xhh | 1 or 2 hexadecimal digits |
\ooo | 1, 2, or 3 octal digits in the range [0-7] |
\a | U+0007: alert (BEL) |
\b | U+0008: backspace (BS): |
\t | U+0009: horizontal tab (HT) |
\n | U+000A: newline/line feed (LF) |
\v | U+000B: vertical tab (VT) |
\f | U+000C: form feed (FF) |
\r | U+000D: carriage return (CR) |
\" | U+0022: double quote |
\' | U+0027: single quote |
\? | U+003F: question mark |
\\ | U+005C: backslash |
Note that when you create an
RWUString from a string literal containing an escaped character, you must use a double-backslash sequence to escape characters, as the C++ compiler itself treats the
\ character as special, denoting the beginning of an escape sequence embedded in the C++ source code. For example:
RWUToUnicodeConverter fromAscii("US-ASCII");
RWUString str("clich\\u00e9", fromAscii);
RWUFromUnicodeConverter toAscii("US-ASCII");
std::cout << str.toBytes(toAscii) << std::endl;
std::cout << str.unescape().toBytes(toAscii) << std::endl;
Results:
========
clich\u00e9
cliché
If an escape sequence is ill-formed,
unescape() throws an
RWConversionErr. (See this class entry in the
SourcePro C++ API Reference Guide.)
3.4.8 String Length
The characteristics of UTF-16 imply that the number of 16-bit code units in an
RWUString may differ from the number of code points. Furthermore, the nature of Unicode implies that the number of code points may differ from the number of characters, as interpreted by the end user. Several methods are provided to determine the length of a string:
The inherited
length() and
codeUnitlength() methods return the number of UTF-16 code units in an
RWUString.
The inherited
codePointLength() method returns the number of code points in an
RWUString.
Note that codePointLength() may be slower than length() or codeUnitLength() because codePointLength() must traverse the string to find code points that arise from surrogate code unit pairs. Since the majority of code points in the current Unicode Standard do not require a surrogate representation, many applications can rely on length() or codeUnitLength() to determine or estimate the number of code points.
An
RWUBreakSearch can also be used to iterate over the characters of an
RWUString, in the context of a particular locale. (See Chapter 7.)
3.4.9 Comparing Strings
RWUString performs comparisons on a lexical basis. Methods such as
compareTo(),
contains(),
first(),
last(),
index(),
rindex(),
strip(), and the global comparison operators compare the bit values of individual code units, not the logical values of code points or characters. In contrast,
RWUCollator performs comparisons on a logical basis, following the conventions specified in a given locale. The logical comparisons made by
RWUCollator are more likely to match an end user's expectations regarding string equality and ordering. The lexical comparisons made by
RWUString, however, are likely to be faster. If two strings contain characters from the same script, and are in the same normalization form, lexical comparisons may be adequate for many purposes. See Chapter 6 for more information on
RWUCollator and locale-sensitive collation.
3.4.10 Accessing SubStrings
In the Internationalization Module,
RWUSubString and
RWUConstSubString provide access to a range of characters within a referenced
RWUString:
The range within a referenced
RWUString is defined by a starting position and an extent. For example, the
7th through the
11th elements, inclusive, would have a starting position of
6 and an extent of
5.
There are no public constructors for substrings. Substrings are constructed by various functions of the
RWUString class. Typically, substrings are created and used anonymously, then destroyed immediately. For example:
RWUString str(“Hello World”);
str(6, 5) = “Mom”;