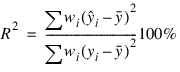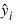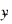POLYREGRESS Function (PV-WAVE Advantage)
Performs a polynomial least-squares regression.
Usage
result = POLYREGRESS(x, y, degree)
Input Parameters
x—One-dimensional array containing the independent variable.
y—One-dimensional array containing the dependent variable.
degree—Degree of the polynomial.
Returned Value
result—An array of size degree + 1 containing the coefficients of the fitted polynomial.
Input Keywords
Double—If present and nonzero, double precision is used.
Weight—Array containing the vector of weights for the observation. If this option is not specified, all observations have equal weights of 1.
Predict_Info—Named variable into which the one-dimensional byte array containing information needed by function POLYPREDICT is stored. The data contained in this array is in an encrypted format and should not be altered before it is used in subsequent calls to POLYPREDICT.
Output Keywords
Ssq_Poly—Named variable into which the array containing the sequential sum of squares and other statistics are stored.
Elements (
i, *) correspond to
xi+1,
i = 0, ..., (
degree – 1), and the contents of the array are described in
Ssq_Poly Array Elements.
Ssq_Lof—Named variable into which the array containing the lack-of-fit statistics is stored.
Elements (i, *) correspond to
x i+1,
i = 0, ..., (
degree – 1), and the contents of the array are described in
Ssq_Lof Array Elements.
XMean—Named variable into which the mean of x is stored.
XVariance—Named variable into which the variance of x is stored.
Anova_Table—Named variable into which the array containing the analysis of variance table is stored. The analysis of variance statistics are given as follows:

0
—degrees of freedom for the model
1
—degrees of freedom for error
2
—total (corrected) degrees of freedom
3
—sum of squares for the model
4
—sum of squares for error
5
—total (corrected) sum of squares
6
—model mean square
7
—error mean square
8
—overall
F-statistic
9
—p-value
10—
R2 (in percent)
11—adjusted
R2 (in percent)
12—estimate of the standard deviation
13—overall mean of
y14—coefficient of variation (in percent)
Df_Pure_Error—Named variable into which the degrees of freedom for pure error is stored.
Ssq_Pure_Error—Named variable into which the sum of squares for pure error is stored.
Residual—Named variable into which the array containing the residuals is stored.
Discussion
Function POLYREGRESS computes estimates of the regression coefficients in a polynomial (curvilinear) regression model. In addition to the computation of the fit, POLYREGRESS computes some summary statistics. Sequential sum of squares attributable to each power of the independent variable (returned by using Ssq_Poly) are computed. These are useful in assessing the importance of the higher order powers in the fit. Draper and Smith (1981, pp. 101–102) and Neter and Wasserman (1974, pp. 278–287) discuss the interpretation of the sequential sum of squares.
The statistic R2 is the percentage of the sum of squares of y about its mean explained by the polynomial curve. Specifically:
where wi is the weight.
is the fitted y value at xi and
is the mean of y. This statistic is useful in assessing the overall fit of the curve to the data. R2 must be between 0% and 100%, inclusive. R2 = 100% indicates a perfect fit to the data.
Estimates of the regression coefficients in a polynomial model are computed using orthogonal polynomials as the regressor variables. This reparameterization of the polynomial model in terms of orthogonal polynomials has the advantage that the loss of accuracy resulting from forming powers of the x-values is avoided. All results are returned to the user for the original model (power form).
Function POLYREGRESS is based on the algorithm of Forsythe (1957). A modification to Forsythe’s algorithm suggested by Shampine (1975) is used for computing the polynomial coefficients. A discussion of Forsythe’s algorithm and Shampine’s modification appears in Kennedy and Gentle (1980, pp. 342–347).
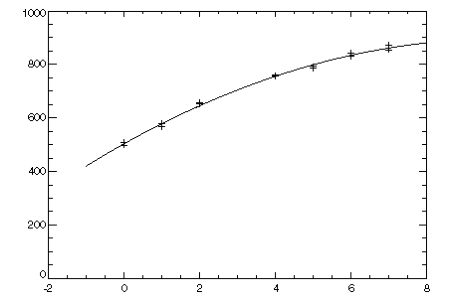
Example 1
A polynomial model is fitted to data discussed by Neter and Wasserman (1974, pp. 279–285). The data set contains the response variable
y measuring coffee sales (in hundred gallons) and the number of self-service coffee dispensers. Responses for fourteen similar cafeterias are in the data set. The results are shown in
Least-Squares Regression Plot.
; Define the data vectors.
x = [0, 0, 1, 1, 2, 2, 4, 4, 5, 5, 6, 6, 7, 7]
y = [508.1, 498.4, 568.2, 577.3, 651.7, 657.0, 755.3, 758.9, $
787.6, 792.1, 841.4, 831.8, 854.7, 871.4]
coefs = POLYREGRESS(x, y, 2)
PM, Coefs, Title = 'Least-Squares Polynomial Coefficients'
; PV-WAVE prints the following:
; Least-Squares Polynomial Coefficients
; 503.346
; 78.9413
; -3.96949
x2 = 9 * FINDGEN(100)/99 - 1
PLOT, x2, coefs(0) + coefs(1) * x2 + coefs(2) * x2^2
OPLOT, x, y, Psym = 1
Example 2
This example is a continuation of the initial example. Here, a procedure is called and defined to output the coefficients and analysis of variance table.
The following procedure prints coefficients and the analysis of variance table.
PRO print_results, coefs, anova_table
coef_labels = ['intercept', 'linear', 'quadratic']
PM, coef_labels, coefs, Title = $
'Least-Squares Polynomial Coefficients',$
Format = '(3a20, /,3f20.4, //)'
anova_labels = ['degrees of freedom for regression', $
'degrees of freedom for error', $
'total (corrected) degrees of freedom', $
'sum of squares for regression', $
'sum of squares for error', $
'total (corrected) sum of squares', $
'regression mean square', $
'error mean square', 'F-statistic', $
'p-value', 'R-squared (in percent)', $
'adjusted R-squared (in percent)', $
'est. standard deviation of model error', $
'overall mean of y', 'coefficient of variation (in percent)']
FOR i=0L, 14 DO PM, anova_labels(i), $
anova_table(i), Format = '(a40, f20.2)'
END
; Define the data vectors.
x = [0, 0, 1, 1, 2, 2, 4, 4, 5, 5, 6, 6, 7, 7]
y = [508.1, 498.4, 568.2, 577.3, 651.7, $
657.0, 755.3, 758.9, 787.6, 792.1, 841.4, 831.8, 854.7, 871.4]
; Call POLYREGRESS with keyword Anova_Table.
Coefs = POLYREGRESS(x, y, 2, Anova_Table = anova_table)
; Call the procedure defined above to output the results.
print_results, coefs, anova_table
This results in the following output:
Least-Squares Polynomial Coefficients
intercept linear quadratic
503.3459 78.9413 -3.9695
* * * Analysis of Variance * * *
degrees of freedom for regression 2.00
degrees of freedom for error 11.00
total (corrected) degrees of freedom 13.00
sum of squares for regression 225031.94
sum of squares for error 710.55
total (corrected) sum of squares 225742.48
regression mean square 112515.97
error mean square 64.60
F-statistic 1741.86
p-value 0.00
R-squared (in percent) 99.69
adjusted R-squared (in percent) 99.63
est. standard deviation of model error 8.04
overall mean of y 710.99
coefficient of variation (in percent) 1.13
Warning Errors
STAT_CONSTANT_YVALUES—The y values are constant. A zero order polynomial is fit. High order coefficients are set to zero.
STAT_FEW_DISTINCT_XVALUES—There are too few distinct x values to fit the desired degree polynomial. High order coefficients are set to zero.
STAT_PERFECT_FIT—A perfect fit was obtained with a polynomial of degree less than degree. High order coefficients are set to zero.
Fatal Errors
STAT_NONNEG_WEIGHT_REQUEST_2—All weights must be nonnegative.
STAT_ALL_OBSERVATIONS_MISSING—Each (x, y) point contains NaN. There are no valid data.
STAT_CONSTANT_XVALUES—The x values are constant.
Version 2017.0
Copyright © 2017, Rogue Wave Software, Inc. All Rights Reserved.